A decent position in the search results is a sure fire way of making more money online. But to do that, you need to make sure your site gets crawled. Here, I'll take you through the basics of how Google crawls the web and what you can do to help it. You might be surprised how easy it is.
So, let’s start at the beginning. Google searches the web. This much you probably know. Then it ranks all the sites and matches them to your query, in order of relevance and authority. SEOs spend a lot of time talking about this part, but much less time talking about how Google actually looks at sites. But it’s important - Google can’t put your site at the top of the search engine results if it doesn’t know you exist.
What actually is ‘Google’?
Whenever you read an article about SEO, the author will almost always talk about "Google" (usually not "Bing" or "the search engines" - Google’s market share is so big, that the smaller ones often don’t get mentioned). But they’re not talking about the company, with offices and marketing departments and all that. They’re talking about the Google algorithm.
The Google algorithm, if you saw it, would look very complicated, incomprehensible even. It’s lines and lines, pages and pages, of mathematical sequences. But unless you become a search engineer at Google, you’re not going to. So phew.
What I‘m about to tell you, and indeed what anyone will ever tell you about the Google algorithm, is what’s presumed to be true. No one outside Google knows exactly how the Google algorithm works because no one has been able to see it. We, the SEO community, can only monitor and record the search results and draw assumptions based on what we see, but we can never ‘know’.
The spider
The first part of what Google does is crawl the web. I'll get onto that in a moment but there a few things we need to cover first. Whenever you read an SEO article, the verbs ‘crawl’ and ‘spider’ and (sometimes) ‘index’ are interchangeable. Google sends out what’s affectionately known as a ‘spider’ to ‘crawl’ the web, going from link to link creating a web (geddit?), and cataloging, or ‘indexing’ what it sees. If you wanted to mimic the actions of the Google spider, start at a big site, like Wikipedia, and click every link you see. Then go to those pages, and click every link and so on. Once you’ve clicked a few hundred billion pages, you’ll be somewhere close.
Google’s spider can only crawl linked pages by the way - it can only access pages that you could access with a mouse. It can’t enter in login details or passwords, and it can’t enter terms in your search bar. As a general rule, if your page isn’t accessible by a clickable link, Google probably won’t see it.
Cache
If you asked 100 people on the street, 99 of them would tell you that Google crawls and indexes the web each and every time you searched for something. This, politely, is nonsense. Yes, Google does crawl ‘the web’, but no, it doesn’t do it in real time (or anything like it).
Google crawls a site as and when it feels it should, and creates what’s called a cache. Cache literally means ‘hidden stash’. It’s a 'screenshot' of your site that Google keeps on its servers. When you run a search, it’s the cache that’s searched, not the real thing.
It also exists as a verb. We say that Google has cached your site to mean ‘Google has seen your site and taken lots of screenshots’. (Screenshots isn’t quite the mot juste, but it’s a good way to visualize what happening. In reality, it stores your sites' text and links.)
So, given that it’s the cache of your site that’s searched, it’s also the cache that will affect your rankings. Google isn’t looking at what your site is like right now, it’s looking at the version that it’s cached. What does that mean in practice? Mostly, that it will take a while for any new content you add to show up in the Google rankings. And, you want to do what you can to make sure your site is cached as often as possible.
Luckily though, there’s a really simple thing you can do to make sure your site is crawled more frequently, and that’s just to add more content. Essentially, each time Google crawls your site, it monitors if there has been any changes. If there has, it makes a note, and remembers to come back a little sooner next time.
If you’re a newspaper website that uploads new content almost constantly, you’ll probably get crawled every few hours. But if you never update your content, or only do very rarely, you’ll probably be crawled every few weeks. Which is bad news.
To see when you were last crawled, just put cache:http://www.YourDomain.com (eg, cache:http://www.wordtracker.com) into Google (or in the navigation bar if you're using Chrome), and it will tell you. Here’s ours.

You can see that ours was crawled on the 4th, which was the day before I took the screenshot. That's pretty good. (And if you can't read this, don't worry. When you do it on your computer, the text will spam the width of your browser, so it'll be much more readable.)
Don’t obsess about how often your site is crawled. Check it once in awhile, if your site hasn’t be crawled in a while, add some more content, but otherwise, don’t stress. It's Google's job to crawl the web, and they do it really well. You no doubt will have bigger SEO fish to fry, but if you want to explore this in more detail, here are nine ways to get your site crawled quicker. So if you’re into this, have a read!
Indexing
So that broadly is crawling. The next step is to ‘index’ the pages ...
The Google index is the list of all the pages that Google has cached. It’s really more of a matrix, in the mathematical sense, with axes related to the key ranking factors like authority and relevance. If that helps you visualize what’s going on, great. We can get into discussions about eigenvalues and eigenvectors another time. But if not, if your idea of the matrix is something involving Keanu Reeves, ignore what I‘ve just said. Swallow the red pill (or was it blue?), go back to your normal life, and know that the Google index is a list and you want every page on your site to be on it.
Deciding which sites go in that list, never mind what order they go in, is actually one of Google’s hardest jobs.
The web is large, very large. Google can’t crawl every page, every day, so it has to choose which fraction of the web it should crawl. It does this by looking at the sites that have the best information, presented in the most accessible way. Sites that do this will get indexed more than sites that don't.
Google will crawl most sites at some point without the site owner really doing anything. (Google, it turns out, is pretty clever.) But if you want to make the search engine's life a little easier (and get more love from it in the process), there are a few things you can do.
Link building
Link building, as well as being great for the rest of your SEO, is a really easy way of simply letting Google know that page exists. When Google crawls the site that’s linking to you, it will then ‘click’ the link and discover your page. Hooray! And of course the more links you have the more authoritative your site becomes in Google’s eyes. So build links. Now.
And that includes internal links by the way. Make sure all your best content is easy to navigate to. Put links to those pages on all the most prominent pages of your site (like, the home page) and Google will be able to find them easily and quickly.
Clean code
Imagine if you were driving somewhere, had to get there quickly, and had a choice of two routes. One would take you straight there on a highway. The other would take you on smaller country roads, most of which involves driving behind a tractor. And some of the road isn’t sealed. Which route would you choose?
If you chose the highway, congratulations, you’re thinking like Google. If your site is written using clean code, Google will read it quickly and is more likely to index you.
If you’re not quite sure what’s the difference between clean code and, er, messy code, you should read how to optimize your code by my colleague Mark. And there’s also a technical checklist you can work through.
Site speed is also a good indicator of how clean your code is, so the article I’ve just linked to will help.
Good navigation
To go back to the driving analogy, if you have somewhere to get to, it’s helpful to have signs to point you in the right direction, otherwise you get lost. Similarly, Google wants you to tell it where your good content is. It needs to know it can get to your best content quickly, so so it can make sure all the best of the web’s content is indexed. Good, keyword rich navigation is part of this. As is having a sitemap
A sitemap
A sitemap is a great way of making sure Google can access your best content quickly. Again, if you were in a car, you’d probably appreciate a map (or a few road signs) to make sure you don’t get lost. You want a road map, Google wants a sitemap. So make one.
Don’t know what one is or how you could set one up? Well, I‘ve written an article just for you.
Google+
It sounds almost too good to be true, but Google loves crawling the sites that people share on it's own social network. So if you've created some awesome content, share it on Google+ straight away, and it's likely to get crawled quickly.
How are you doing?
So, you’ve learned some theory. But how is your site actually being viewed right now?
Google's Webmaster Tools is a brilliant (free) tool from Google that lets you see how your site is performing in Google's eyes. If you've not got an account already, it's worth setting one up as it helps you spot loads of errors with your site. But this article is about crawling, so let's look at that.
Log into Webmaster Tools and click ‘crawl errors’.
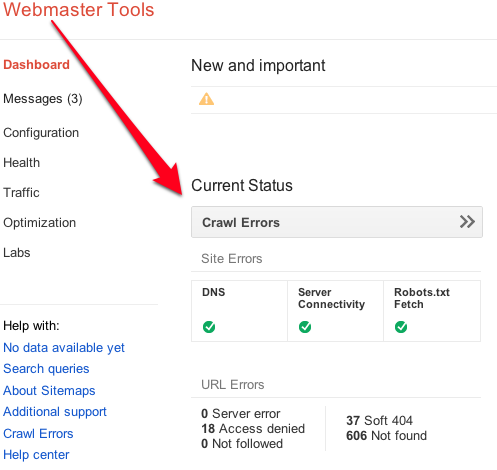
Now on the left hand side, click ‘Index status’ then, after that page loads, click ‘Advanced’. And you’ll see something like this.
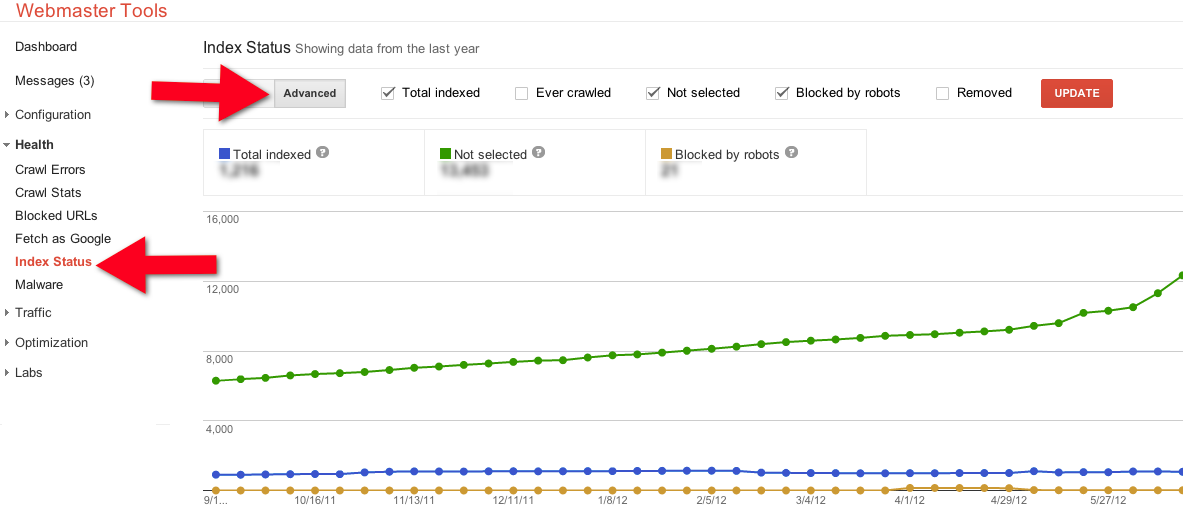
The key lines you need to look at here are the blue and the green.
The blue is the number of pages that have been indexed, ie, are ranking somewhere on your site. You want this line to go up.
The green are the pages that Google has crawled but is not indexing. There are two reasons for this, one good, and one bad.
The good reason is that you may have put a redirect in, so Google crawled that page but was told not to bother indexing it. Similarly, you might have put a canonical tag in there, so Google knows that you’re repeating your content, no dramas. (Why Google doesn’t separate these pages out, I’m afraid I have no idea.)
The bad news is that they also don’t index content which has similar content to other pages. Content which you’ve not redirected or canonically tagged, but Google has nonetheless deemed it to be duplicate. Google doesn't like duplicate content – if it has to crawl the same content lots of times, that’s just a waste of time. And what’s another word for time? Money.
If you do have lots of duplicate content, read what we have to say about the canonical tag and redirects, and we might be able to help you.
Webmaster Tools is a really great resource to see how Google views your website. It flags up problems and let’s you ‘feed back’ to Google. You can nudge its algorithm in the right direction and see the results in the search pages. There’s much to learn about Webmaster Tools and how Google sees your site, but as a next step, may I recommend SEO indexing?